
2023-1. 빅데이터 애널리틱스 통계분석 2주차. ANOVA, 상관분석
1. ANOVA 분석
- 정의 : 세 집단 이상의 평균 차이를 비교하고자 할 때 사용하는 통계적 분석 방법
- 구성 : 독립변수(명목척도), 종속변수(등간 or 비율척도)
· 가설) 귀무가설 : 모든 집단의 평균은 같다.
대립가설 : 모든 집단의 평균이 모두 같지는 않다. (적어도 두 집단 간의 평균 차이는 있다.)
예) 직업 간 디자인 만족접수 평균이 모두 같지는 않다.
1-1. SPSS 분석
- 분석 > 평균비교(M) > 일원배치 분산분석(O)
· 독립변수 → '요인' 입력
· 종속변수 → '종속변수' 입력
· 옵션 - 기술통계(D), 분산 동질성 검정(H) 체크 후 확인
1-2. 결과해석
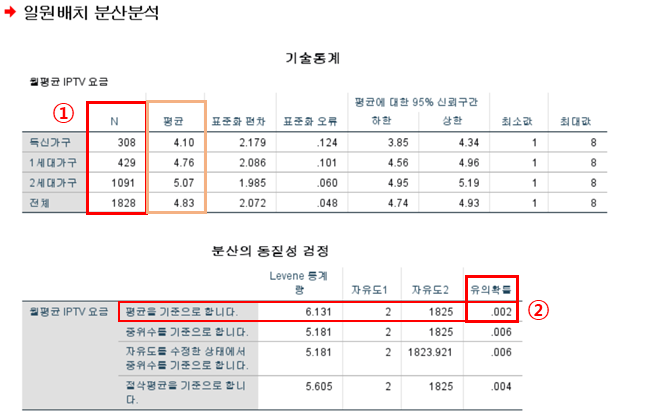
1) [기술통계]표 : N 확인 (N > 30이면 정규성 만족)
2) [분산의 동질성 검정]표 : 등분산 검정
- Levene 통계량) 평균을 기준으로 합니다 - 유의확률 p > 0.05 → 귀무가설(모든 집단은 등분산이다) 채택
: 사후분석 시 「등분산을 가정」함
3) [ANOVA]표 : 유의확률 p < 0.05 → 귀무가설(모든 집단의 평균은 같다) 기각
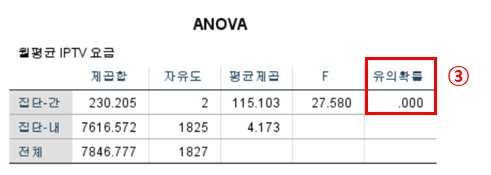
→ 그래서 집단 누구랑 누가 평균 차이가 있는데?! → 사후분석을 통한 집단 간 차이 확인
2. 사후 분석 (post-hoc test)
- 정의 : 집단 간 차이를 사후적으로 검증
- 조건별 분석방법 선택 : 1) 샘플 수 동일 여부, 2) 등분산 가정 여부
2-1. SPSS 분석
- 분석 > 평균비교(M) > 일원배치 분산분석(O)
· 사후분석 : Bonferroni, Scheffe, Turkey, Duncan, Dunnett, Games-Howell 선택 후 확인
2-2. 결과해석
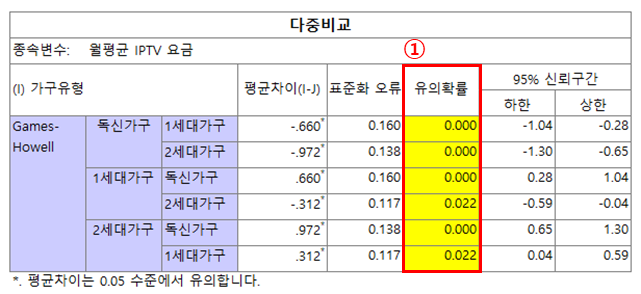
1. [다중비교] : 집단 간 평균 차이를 모든 경우의 수로 보여줌
- 유의확률로 집단 간 차이 확인 가능
· 유의확률 p > 0.05 → 집단 간 평균 차이가 없다.
p < 0.05 → 집단 간 평균 차이가 있다.
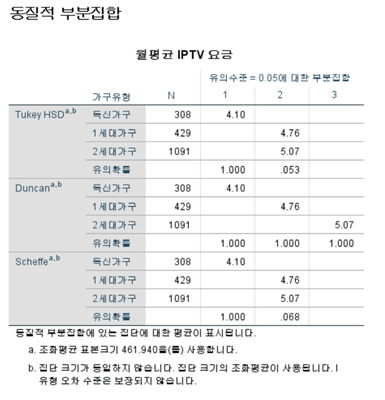
2. [동질적 부분집합] : 어느 집단에 응답범주가 속해있는 지 확인
3. Pearson 상관분석
- 정의 : 양적인 두 변수 간의 관계가 유의한지 확인하는 분석 (인과관계 확인 X)
- 가설 : 귀무가설) 두 변수 간의 상관관계가 없다. (두 변수는 차이가 없다)
대립가설) 두 변수 간의 상관관계가 있다.
3-1. SPSS 분석
- 분석 > 상관분석(C) > 이변량 상관(B)
· 변수 칸에 확인하고자 하는 변수 이동
· 상관관계 : Pearson 체크
· 유의성 검정 : 양측 선택
· 유의한 상관계수 플래그 체크 후 확인
3-2. 결과해석
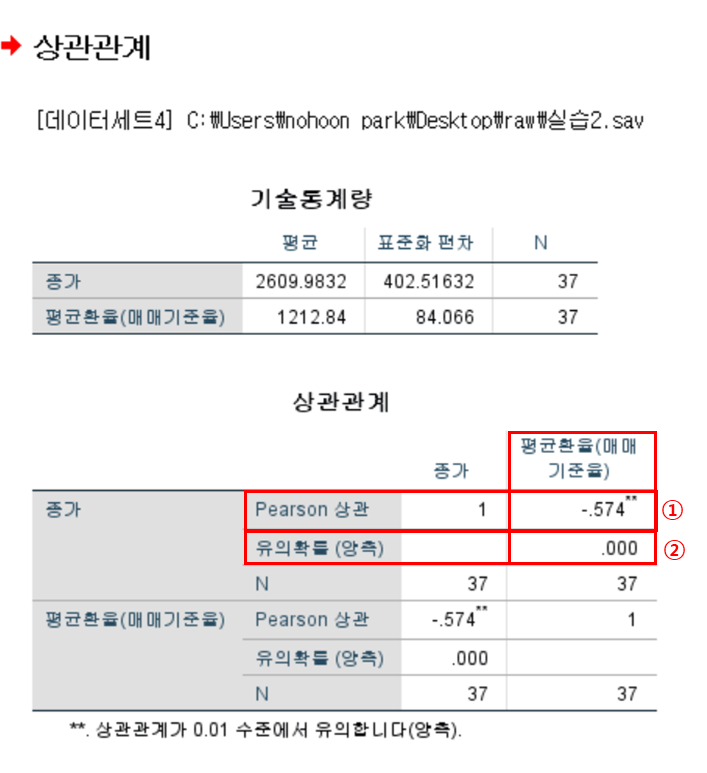
1. [상관관계]표
1) pearson 상관계수(r) : 두 변수의 상관관계 확인
r의 범위 : -1 ~ 1, 0에 가까울수록 상관관계가 없다.
2) 유의확률(양측) : 두 변수가 실제로 선형을 이루는 관계인지 확인
p < 0.05 → 귀무가설(두 변수 간 상관관계가 없다) 기각
참고) 그래프 > 래거시 대화상자(L) > 산점도/점도표(S)
· 단순 산점도 - 정의 선택, X축, Y축 입력2
'빅데이터 대학원 > 2023-1. 빅데이터애널리틱스통계분석' 카테고리의 다른 글
| 2023-1. 빅데이터 애널리틱스 통계분석 4주차. 로지스틱 회귀분석 (0) | 2023.04.06 |
|---|---|
| 2023-1. 빅데이터 애널리틱스 통계분석 3주차. 회귀분석 (0) | 2023.04.05 |
| 2023-1. 빅데이터 애널리틱스 통계분석 1주차. 기초통계 (t.test) (0) | 2023.04.03 |


