
2023-1. 빅데이터 애널리틱스 통계분석 4주차. 로지스틱 회귀분석
1. 로지스틱 회귀분석
- 정의 : 종속변수가 0 또는 1, 참 또는 거짓 등 두가지 값 중 하나만 취할 수 있는 경우, 로지스틱 회귀분석을 사용하여 분석/예측
- 조건 : 종속변수 (명목 or 서열척도) ex) Y/N
독립변수(등간 or 비율척도) - 연속형 변수
1-1. SPSS 분석
- 분석 > 회귀분석(R) > 이분형 로지스틱(G)
· 0, 1 코딩변수 → 종속변수
· 독립변수들 → 공변량 입력
· 옵션 > hosmer-Lemeshow 적합도, exp(B) : 신뢰구간 : 95% 체크
· 방법 : 입력
1-2. 결과해석 (블록1 확인)
0. 종속변수 인코딩 값 확인

1. [모형계수의 총괄검정] : 모형 - 유의확률 p <0.05 확인
- 종속변인을 구분하는 데 투입한 독립변인들은 유효한 지 검정
- 카이제곱이 클수록 적합도가 높다.
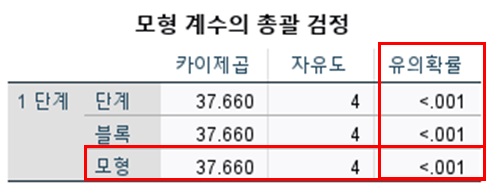
2. [모형요약]
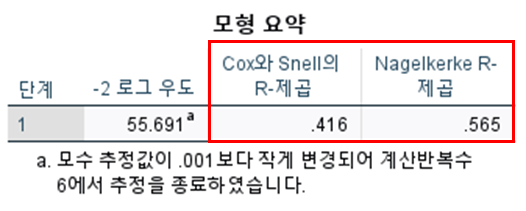
- -2로그 우도 : 값이 작을수록 적합도가 높다. (0=최적, 절대적인 것 X)
- Cox와 Snell의 R-제곱, Nagelkerke R-제곱 : 범위 0 ~ 1, 설명력
3. [Hosmer와 Lemeshow 검정] : 회귀모형의 적합도 설명
- 불일치 정도. 유의확률 p >0.05 여야 한다. → 귀무가설 채택 (모형이 적합하다)

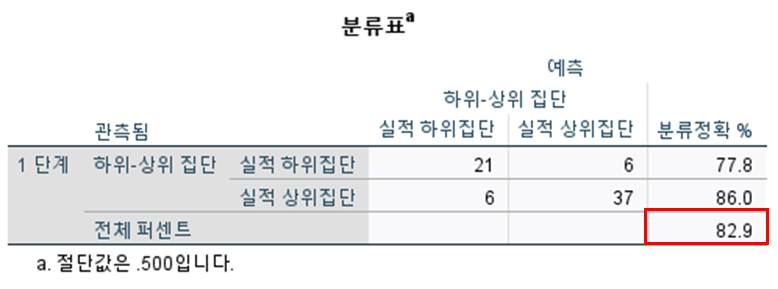
4. [분류표] : Hit Ratio (분류정확도)
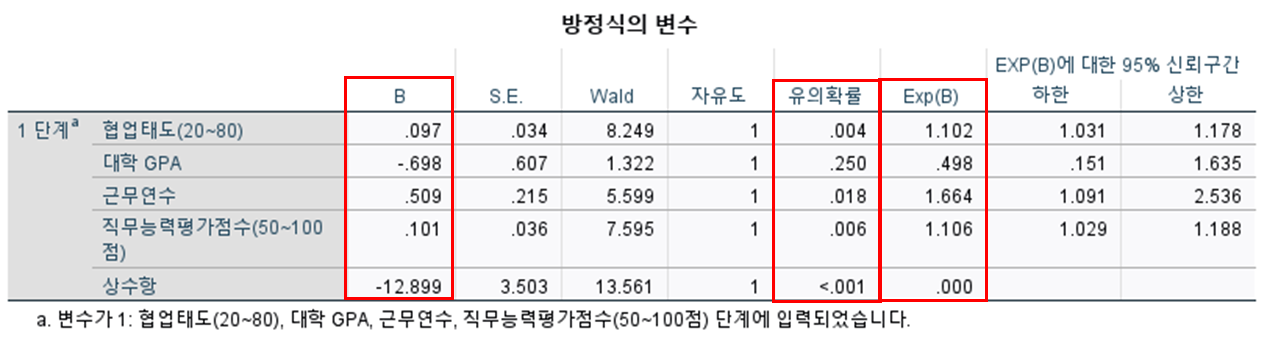
5. [방정식의 변수]
1) B : 양수인 경우) 클수록 집단2(내부값 1)에 포함될 가능성 ↑
음수인 경우) 클수록 집단1(내부값 0)에 포함될 가능성 ↑
2) 유의확률 p < 0.05 (통계적으로 유의하다)
3) Exp(B) : 유의확률이 범위 내라면, Exp(B)가 x배 높다.
- 독립변수가 1 증가하면, 종속변수는 Exp(B) 만큼 증가한다.
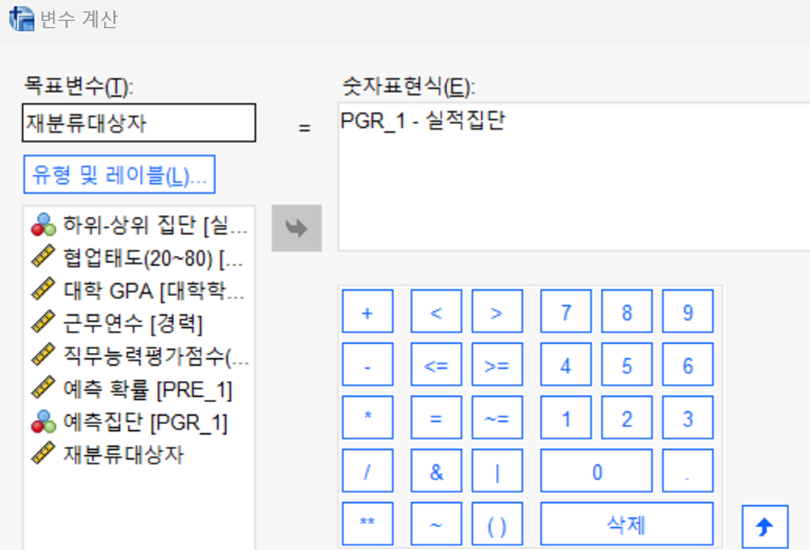
1-2-1. 기존 케이스 집단 재분류 (0.5 기준)
· Pre_1 : 집단2(내부값 1) 분류 확률
· PGR_1 : 재분류 집단
- SPSS 분석 (재분류)
· 변환 > 변수계산 > 목표변수, 숫자표현식 입력
- 새로운 케이스 분류 확률 예측
· 오즈비 Odds ratio
· 오즈비값은 집단2(내부값 1)에 속할 확률의 비율
'빅데이터 대학원 > 2023-1. 빅데이터애널리틱스통계분석' 카테고리의 다른 글
| 2023-1. 빅데이터 애널리틱스 통계분석 3주차. 회귀분석 (0) | 2023.04.05 |
|---|---|
| 2023-1. 빅데이터 애널리틱스 통계분석 2주차. ANOVA, 상관분석 (0) | 2023.04.04 |
| 2023-1. 빅데이터 애널리틱스 통계분석 1주차. 기초통계 (t.test) (0) | 2023.04.03 |


